Микропроцессоры Pentium, так же, как и его предшественники (начиная с 80268), могут работать в двух режимах: реального адреса и виртуального защищенного адреса. Обычно эти режимы называют просто реальным и защищенным. В реальном режиме 32-разрядные микропроцессоры функционируют фактически так же, как МП 86 с повышенным быстродействием и расширенным набором команд. Многие весьма привлекательные возможности микропроцессоров принципиально не реализуются в реальном режиме, который введен лишь для обеспечения совместимости с предыдущими моделями процессоров. Характерной особенностью реального режима является ограничение объема адресуемой оперативной памяти величиной 1 Мбайт.
Только перевод микропроцессора в защищенный режим позволяет полностью реализовать все возможности, загаженные в его архитектуру и недоступные в реальном режиме. Сюда можно отнести:
- увеличение адресуемого пространства до 4 Гбайт;
- возможность работать в виртуальном адресном пространстве, превышающем максимально возможный объем физической памяти и составляющем огромную величину 64 Тбайт;
- организация многозадачного режима с параллельным выполнением нескольких программ (процессов). Собственно говоря, многозадачный режим организует многозадачная операционная система, однако микропроцессор предоставляет необходимый для этого режима мощный и надежный механизм защиты задач друг от друга с помощью четырехуровневой системы привилегий;
- страничная организация памяти, повышающая уровень защиты задач
друг от друга и эффективность их выполнения.
При включении микропроцессора в нем автоматически устанавливается режим реального адреса. Переход в защищенный режим осуществляется программно путем выполнения соответствующей последовательности команд. Поскольку многие детали функционирования микропроцессора в реальном и защищенном режимах существенно различаются, программы, предназначенные для защищенного режима, должны быть написаны особым образом. При этом различия реального и защищенного режимов настолько велики, что программы реального режима не могут выполняться в защищенном режиме и наоборот. Другими словами, реальный и защищенный режимы не совместимы.
Архитектура современного микропроцессора необычайно сложна. Столь же сложными оказываются и средства защищенного режима, а также программы, использующие эти средства. С другой стороны, при решении многих прикладных задач (например, при отладке приложений Windows, работающих, естественно, в защищенном режиме), нет необходимости в понимании всех деталей функционирования защищенного режима; достаточно иметь знакомство с его основными понятиями. В настоящем разделе дается краткое описание основ защищенного режима и его наиболее важных структур и алгоритмов функционирования.
Пожалуй, наиболее важным отличием защищенного режима от реального является иной принцип формирования физического адреса. Вспомним, что в реальном режиме физический адрес адресуемой ячейки памяти состоит из двух компонентов - сегментного адреса и смещения. Оба компонента имеют размер 16 бит, и процессор, обращаясь к памяти, пользуется следующим правилом вычисления физического адреса:
Физический адрес = сегментный адрес * 16 + смещение
И сегментный адрес, и смещение не могут быть больше FFFFh, откуда следуют два важнейших ограничения реального режима: объем адресного пространства составляет всего 1 Мбайт, а сегменты не могут иметь размер, превышающий 64 Кбайт.
В защищенном режиме программа по-прежнему состоит из сегментов, адресуемых с помощью 16-разрядных сегментных регистров, однако местоположение сегментов в физической памяти определяется другим способом.
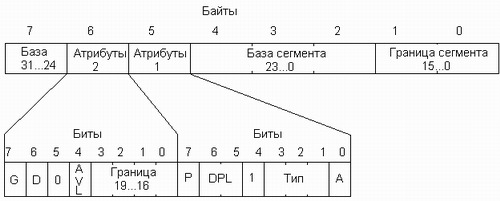
В сегментные регистры в защищенном режиме записываются не сегментные адреса, а так называемые селекторы, биты 3...15 которых рассматриваются, как номера (индексы) ячеек специальной таблицы, содержащей дескрипторы сегментов программы. Таблица дескрипторов обычно создастся операционной системой защищенного режима (например, системой Windows) и, как правило, недоступна программе. Каждый дескриптор таблицы дескрипторов имеет размер 8 байт, и в нем хранятся все характеристики, необходимые процессору для обслуживания этого сегмента. Среди этих характеристик необходимо выделить в первую очередь две: адрес сегмента и его длину (рис. 4.4).
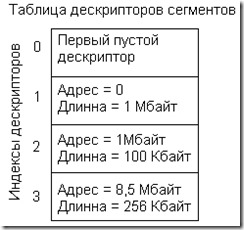
Рис. 4.4. Дескрипторы сегментов и их селекторы.
Под адрес сегмента в дескрипторе выделяется 32 бит, и, таким образом, сегмент может начинаться в любой точке адресного пространства объемом 23- = 4 Гбайт. Это адресное пространство носит название линейного. В простейшем случае, когда выключено страничное преобразование, о котором речь будет идти позже, линейные адреса отвечают физическим. Таким образом, процессор может работать с оперативной памятью объемом до 4 Гбайт.
Как и в реальном режиме, адрес адресуемой ячейки вычисляется процессором, как сумма базового адреса сегмента и смещения:
Линейный адрес = базовый адрес сегмента + смещение
В 32-разрядных процессорах смещение имеет размер 32 бит, поэтому максимальная длина сегмента составляет 2" = 4 Гбайт.
На рис. 4.4 приведен гипотетический пример программы, состоящей из трех сегментов, первый из которых имеет длину 1 Мбайт и расположен в начале адресного пространства, второй, размером 100 Кбайт, вплотную примыкает к первому, а третий, имеющий размер всего 256 байт, расположен в середине девятого по счету мегабайта.
Адреса, используемые программой для обращения к ячейкам памяти, и состоящие всегда из двух компонентов - селектора и смещения - иногда называются виртуальными. Система сегментной адресации преобразует виртуальные адреса в линейные. Поскольку таблица дескрипторов, с помощью которой осуществляется это преобразование, обычно недоступна программе, программа может не знать, в каких именно участках логического адресного пространства находятся се компоненты. Фактически это сводится к тому, что, загружая программу в память, вы не знаете, в каких местах памяти будут находиться ее сегменты, и каков будет порядок их размещения. Программисту доступны только виртуальные адреса, преобразование же их в линейные и затем в физические берет на себя операционная система.
Каков объем виртуального адресного пространства? Программа указывает номер нужного ей дескриптора с помощью селектора, в котором для индекса дескриптора отведено 13 бит. Отсюда следует, что в дескрипторной таблице может быть до 1" = 8. К дескрипторов. Однако в действительности их в два раза больше, так как программа может работать не с одной, а с двумя дескрипторными таблицами - одной глобальной, разделяемой всеми выполняемыми задачами, и одной локальной, принадлежащей конкретной задаче. В селекторе предусмотрен специальный бит (бит 2), состояние которого говорит о типе требуемой программе дескрипторной таблицы. Таким образом, всего программе могут быть доступны 214 = 16 К дескрипторов, т.е. 16 К сегментов. Поскольку размер каждого сегмента, определяемый максимальной величиной смещения, может достигать 2-1 = 4 Гбайт, объем виртуального адресного пространства оказывается равным 16 К * 4 Кбайт = = 64 Тбайт.
Реально, однако, оперативная память компьютера с 32-разрядной адресной шиной не может быть больше 4 Гбайт, т.е. при сделанных выше предположениях (16 К сегментов размером 4 Гбайт каждый) в памяти может поместиться максимум один сегмент из более чем 16 тысяч. Где же будут находиться все остальные?
Полный объем виртуального пространства может быть реализован только с помощью многозадачной операционной системы, которая хранит все неиспользуемые в настоящий момент сегменты на диске, загружая их в память по мере необходимости. Разумеется, если мы хотим полностью реализовать возможности, заложенные в современные процессоры, нам потребуется диск довольно большого объема - 64 Тбайт. Однако и при нынешних более скромных технических средствах (память до 100 Мбайт, жесткий диск до 10 Гбайт) принцип виртуальной памяти используется всеми многозадачными операционными системами с большой эффективностью. С другой стороны, для прикладного программиста этот вопрос не представляет особого интереса, так как сброс сегментов на диск и подкачка их с диска осуществляются операционной системой, а не программой, и вмешательство эту процедуру вряд ли целесообразно.
Как уже отмечалось, адрес, вычисляемый процессором на основе селектора и смещения, относится к линейному адресному пространству, не обязательно совпадающему с физическим. Преобразование линейных адресов в физические осуществляется с помощью так называемой страничной трансляции, частично реализуемой процессором, а частично - операционной системой. Если страничная трансляция выключена, все ли-нейные адреса в точности совпадают с физическими; если страничная трансляция включена, то линейные адреса преобразуются в физические в соответствии с содержимым страничных таблиц (рис. 4.5).
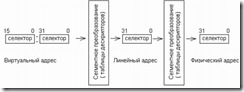
Рис. 4.5. Цепочка преобразований виртуального адреса в физический.
Страницей называется связный участок линейного или физического адресного пространства объемом 4 Кбайт. Программа работает в линейном адресном пространстве, не подозревая о существовании страничного преобразования или даже самих страниц. Механизм страничной трансляции отображает логические страницы на физические в соответствии с информацией, содержащейся в страничных таблицах. В результате отдельные 4х-килобайтовыс участки программы могут реально находиться в любых несвязных друг с другом 4х-килобайтовых областях физической памяти (рис. 4.6). Порядок размещения физических страниц в памяти может не соответствовать (и обычно не соответствует) порядку следования логических страниц. Более того, некоторые логические страницы могут перекрываться, фактически сосуществуя в одной и той же области физической памяти.
Страничная трансляция представляет собой довольно сложный механизм, в котором принимают участие аппаратные средства процессора и находящиеся в памяти таблицы преобразования. Назначение и взаимодействие элементов системы страничной трансляции схематически изображено на рис. 4.7.
Система страничных таблиц состоит из двух уровней. На первом уровне находится каталог таблиц страниц (или просто каталог страниц) - резидентная в памяти таблица, содержащая 1024 4х-байтовых поля с адресами таблиц страниц. На втором уровне находятся таблицы страниц, каждая из которых содержит так же 1024 4х-байтовых поля с адресами физических страниц памяти. Максимально возможное число таблиц страниц определяется числом полей в каталоге и может доходить до 1024. Поскольку размер страницы составляет 4 Кбайт, 1024 таблицы по 1024 страницы перекрывают все адресное пространство (4 Гбайт).
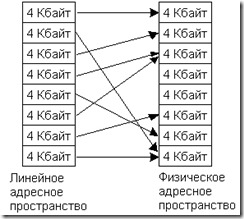
Рис. 4.6. Отображение логических адресов на физические.
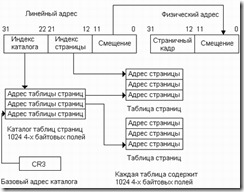
Рис. 4.7. Страничная трансляция адресов.
Не все 1024 таблицы страниц должны обязательно иметься в наличии (кстати, они заняли бы в памяти довольно много места - 4 Мбайт). Если программа реально использует лишь часть возможного линейного адресного пространства, а так всегда и бывает, то неиспользуемые поля в каталоге страниц помечаются, как отсутствующие. Для таких полей система, экономя память, не выделяет страничные таблицы.
При включенной страничной трансляции линейный адрес рассматривается, как совокупность трех полей: 10-битового индекса в каталоге страниц, 10-битовбго индекса в выбранной таблице страниц и 12-битового смещения в выбранной странице. Напомним, что линейный адрес образуется путем сложения базового адреса сегмента, взятого из дескриптора сегмента, и смещения в этом сегменте, предоставленного программой.
Старшие 10 бит линейного адреса образуют номер поля в каталоге страниц. Базовый адрес каталога хранится в одном из управляющих регистров процессора, конкретно, в регистре CR3. Из-за того, что каталог сам представляет собой страницу и выровнен в памяти на границу 4 Кбайт, в регистре CR3 для адресации к каталогу используются лишь старшие 20 бит, а младшие 12 бит зарезервированы для будущих применений.
Поля каталога имеют размер 4 байт, поэтому индекс, извлеченный из линейного адреса, сдвигается влево на 2 бит (т.е. умножается на 4) и полученная величина складывается с базовым адресом каталога, образуя адрес конкретного поля каталога. Каждое поле каталога содержит физический базовый адрес одной из таблиц страниц, причем, поскольку таблицы страниц сами представляют собой страницы и выровнены в памяти на границу 4 Кбайт, в этом адресе значащими являются только старшие 20 бит.
Далее из линейного адреса извлекается средняя часть (биты 12...21), сдвигается влево на 2 бит и складывается с базовым адресом, хранящимся в выбранном поле каталога. В результате образуется физический адрес страницы в памяти, в котором опять же используются только старшие 20 бит. Этот адрес, рассматриваемый, как старшие 20 бит физического адреса адресуемой ячейки, носит название страничного кадра. Страничный кадр дополняется с правой стороны младшими 12 битами линейного адреса, которые проходят через страничный механизм без изменения и играют роль смещения внутри выбранной физической страницы.
Рассмотрим абстрактный пример, позволяющий проследить цепочку преобразования виртуального адреса в физический. Пусть программа выполняет команду
mov ЕАХ,DS:[ЕВХ]
при этом содержимое DS (селектор) составляет 1167И, а содержимое ЕВХ (смещение) 31678U.
Старшие 13 бит селектора (число 116U) образуют индекс дескриптора в системной дескрипторной таблице. Каждый дескриптор включает в себя довольно большой объем информации о конкретном сегменте и, в частности, его линейный адрес. Пусть в ячейке дескрипторной таблицы с номером 116h записан линейный адрес (базовый адрес сегмента) 0l0Sl000h.
Тогда полный линейный адрес адресуемой ячейки определится, как сумма базового адреса и смещения:
Базовый адрес сегмента 0l0Sl000h
Смещение 0003167811
Полный линейный адрес 0108267811
При выключенной табличной трансляции величина 010826У811 будет представлять собой абсолютный физический адрес ячейки, содержимое которой должно быть прочитано приведенной выше командой mov. Легко сообразить, что эта ячейка находится в самом начале 17-го мегабайта оперативной памяти.
Посмотрим, как будет образовываться физический адрес при использовании страничной трансляции адресов. Полученный линейный адрес надо разделить на три составляющие для выделения индексов и смещения (рис. 4.8)

Рис. 4.8. Пример линейного адреса.
Индекс каталога составляет 4h. Умножение его на 4 даст смещение от начала каталога. Это смещение равно 10h.
Индекс таблицы страниц оказался равным 82h. После умножения на 4 получаем смещение в таблице страниц, равное в данном случае 210h.
Предположим, что регистр CR3 содержит число S000h. Тогда физический адрес ячейки в каталоге, откуда надо получить адрес закрепленной за данным участком программы таблицы страниц, составит S000h + l0h = 8010h. Пусть по этому адресу записано число 4602lh. Его 12 младших битов составляют служебную информацию (в частности, бит 1 свидетельствует о присутствии этой таблицы страниц в памяти, а бит 5 говорит о том, что к этой таблице уже были обращения), а старшие биты, т.е. число 46000h образуют физический базовый адрес таблицы страниц. Для получения адреса требуемой ячейки этой таблицы к базовому адресу надо прибавить смещение 210h. Результирующий адрес составит 462101г.
Будем считать, что по адресу 4621011 записано число 01FF502111. Отбросив служебные биты, получим адрес физической страницы в памяти 01FF5000U. Этот адрес всегда оканчивается тремя нулями, так как страницы выровнены в памяти на границу 4 Кбайт. Для получения физического адреса адресуемой ячейки следует заполнить 12 младших бит полученного адреса битами смещения из линейного адреса нашей ячейки, в которых в нашем примере записано число 678h. В итоге получаем физический адрес памяти 01FF567811, расположенный в конце 32-го Мбайта.
Как видно из этого примера, и со страничной трансляцией, и без нее вычисление физических адресов адресуемых ячеек выполняется в защищенном режиме совсем не так, как в реальном. Неприятным практическим следствием правил адресации защищенного режима является уже упоминавшаяся "оторванность" прикладной программы от физической памяти. Программист, отлаживающий программу защищенного режима (например, приложение Windows), может легко заглянуть в сегментные регистры и определить селекторы, выделенные программе. Однако селекторы абсолютно ничего не говорят о физических адресах, используемых программой. Физические адреса находятся в таблицах дескрипторов, а эти таблицы недоступны прикладной программе. Таким образом, программист не знает, где в памяти находится его программа или используемые ею области данных.
С другой стороны, использование в процессе преобразования адресов защищенных системой таблиц имеет свои преимущества. Обычно многозадачная операционная система создает для каждой выполняемой задачи свой набор таблиц преобразования адресов. Это позволяет каждой из задач использовать весь диапазон виртуальных адресов, при этом, хотя для разных задач виртуальные адреса могут совпадать (и, как правило, по крайней мере частично совпадают), однако сегментное и страничное преобразования обеспечивают выделение для каждой задачи несовпадающих областей физической памяти, надежно изолируя виртуальные, адресные пространства задач друг от друга.
Вернемся теперь к таблицам дескрипторов и рассмотрим их более детально. Существует два типа дескрипторных таблиц: таблица глобальных дескрипторов (GDT от Global Descriptor Table) и таблицы локальных дескрипторов (LDT от Local Descriptor Table).Обычно для каждой из этих таблиц в памяти создаются отдельные сегменты, хотя в принципе это не обязательно. Таблица глобальных дескрипторов существует в единственном экземпляре и обычно принадлежит операционной системе, а локальных таблиц может быть много (это типично для многозадачного режима, в котором каждой задаче назначается своя локальная таблица).
Виртуальное адресное пространство делится на две равные половины. К одной половине обращение происходит через GDT, к другой половине через LDT. Как уже отмечалось, все виртуальное пространство состоит из 214 сегментов, из которых 213 сегментов адресуются через GDT, и еще 213 - чрез LDT.
Когда многозадачная система переключает задачи, глобальная таблица остается неизменной, а текущая локальная таблица заменяется на локальную таблицу новой задачи. Таким образом, половина виртуального пространства в принципе доступна всем задачам в системе, а половина переключается от одной задачи к другой по мере переключения самих задач.
Для программирования защищенного режима и даже для отладки прикладных программ, работающих в защищенном режиме, полезно представлять себе структуру дескриптора и смысл его отдельных полей. Следует заметить, что существует несколько типов дескрипторов, которым присущи разные форматы. Так, дескриптор сегмента памяти (наиболее распространенный тип дескриптора) отличается от дескриптора шлюза, используемого, в частности, для обслуживания прерываний. Рассмотрим формат дескриптора памяти (рис. 4.9).
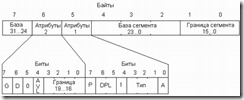
Рис. 4.9. Формат дескриптора памяти.
Как видно из рисунка, дескриптор занимает 8 байт. В байтах 2...4 и 7 записывается линейный базовый адрес сегмента. Полная длина базового адреса - 32 бит. В байтах 0-1 записываются младшие 16 бит границы сегмента, а в младшие четыре бита байта атрибутов 2 - оставшиеся биты 16...19. Границей сегмента называется номер его последнего байта. Мы видим, что граница описывается 20-ю битами, и ее численное значение не может превышать 1М. Однако, единицы, в которых задается граница, можно изменять, что осуществляется с помощью бита дробности G (бит 7 байта атрибутов 2). Если G=0, граница указывается в байтах; если 1 - в блоках по 4 Кбайт. Таким образом, размер сегмента можно задавать с точностью до байта, но тогда он не может быть больше 1 Мбайт; если же установить G=l, то сегмент может достигать 4 Гбайт, однако его размер будет кратен 4 Кбайт. База сегмента и в том, и в другом случае задастся с точностью до байта.
Рассмотрим теперь атрибуты сегмента, которые занимают два байта дескриптора.
Бит A (Accessed, было обращение) устанавливается процессором в тот момент, когда в какой-либо сегментный регистр загружается селектор данного сегмента. Далее процессор этот бит не сбрасывает, однако его может сбросить программа (разумеется, если она имеет доступ к содержимому дескриптора, что обычно является прерогативой операционной системы). Анализируя биты обращения различных сегментов, программа может судить о том, было ли обращение к данному сегменту' после того, как она сбросила бит А.
Тип сегмента занимает 3 бит (иногда бит А включают в поле типа, и тогда тип занимает 4 бит) и может иметь 8 значений. Тип определяет правила доступа к сегменту. Так, если сегмент имеет тип 1, для него разрешены чтение и запись, что характерно для сегментов данных. Назначив сегменту тип 0, мы разрешим только чтение этого сегмента, защитив его тем самым от любых модификаций. Тип 4 обозначает разрешение исполнения, что характерно для сегментов команд. Используются и другие типы сегментов.
Подчеркнем, что защита сегментов памяти от несанкционированных его типом действий выполняется не программой, и даже не операционной системой, а процессором на аппаратном уровне. Так, при попытке записи в сегмент типа 0 возникнет так называемое исключение общей защиты. Исключением называется внутреннее прерывание, возбуждаемое процессором при возникновении каких-либо неправильных с его точки зрения ситуаций. Попытка записи в сегмент, для которого запись запрещена, и относится к такого рода ситуациям. Исключению общей защиты соответствует вектор 13, в котором должен находиться адрес обработчика этого исключения.
Стоит еще обратить внимание на тип 4. Для сегмента команд разрешается только исполнение, но не запись и даже не чтение. Это значит, что в защищенном режиме программа не может случайно залезть в свой сегмент команд и затереть его; не может она также и сознательно модифицировать команды в процессе своего выполнения - методика, иногда используемая в программах реального режима для защиты от их расшифровки любознательными программистами
Бит 4 байта атрибутов 1 является идентификатором сегмента. Если он равен 1, как это показано на рис. 4.9, дескриптор описывает сегмент памяти. Значение этого бита 0 характеризует дескриптор системного сегмента.
Поле DPL (Descriptor Privilege Level, уровень привилегий дескриптора) служит для защиты программ друг от друга. Уровень привилегий может принимать значения от 0 (максимальные привилегии) до 3 (минимальные). Программам операционной системы обычно назначается уровень 0, прикладным программам - уровень 3, в результате чего исключается возможность некорректным программам разрушить операционную систему. С другой стороны, если прикладная программа сама выполняет функции операционной системы, переводя процессор в защищенный режим и работая далее в этом режиме, ее сегментам следует назначить наивысший (нулевой) уровень привилегий, что откроет ей доступ ко всем средствам защищенного режима.
Бит Р говорит о присутствии сегмента в памяти. В основном он используется для организации виртуальной памяти. С помощью этого бита система может определить, находится ли требуемый сегмент в памяти, и при необходимости загрузить его с диска. В процессе выгрузки ненужного пока сегмента на диск бит Р в его дескрипторе сбрасывается.
Младшая половина байта атрибутов 2 занята старшими битами границы сегмента. Бит AVL (от Available, доступный) не используется и не анализируется процессором и предназначен для использования прикладными программами.
Бит D (Default, умолчание) определяет действующий по умолчанию размер для операндов и адресов. Он изменяет характеристики сегментов двух типов: исполняемых и стека. Если бит D сегмента команд равен 0, в сегменте по умолчанию используются 16-битовые адреса и операнды, если 1 - 32-битовые.
Атрибут сегмента, действующий по умолчанию, можно изменить на противоположный с помощью префиксов замены размера операнда (66h) и замены размера адреса (67п). Таким образом, для сегмента с D=0 префикс 66h перед некоторой командой заставляет ее рассматривать свои операнды, как 32-битовые, а для сегмента с D=l тот же префикс 66h, наоборот, сделает операнды 16-битовыми. В некоторых случаях транслятор сам включает в объектный модуль необходимые префиксы, в других случаях их приходится вводить в программу "вручную".
Рассмотрим теперь для примера простую программу, которая, будучи запущена обычным образом под управлением MS-DOS, переключает процессор в защищенный режим, выводит на экран для контроля символ, переходит назад в реальный режим (чтобы не вывести компьютер из равновесия) и завершается стандартным для DOS образом.
Для того, чтобы наша программа могла бы хоть что-то сделать в защищенном режиме, для нее необходимо создать среду защищенного режима, в первую очередь, таблицу глобальных дескрипторов с описанием всех сегментов, с которыми программа будет работать. Кроме нас никто эту таблицу (при работе в DOS) не создаст. Таким образом, наша программа будет в какой-то мере выполнять функции операционной системы защищенного режима.
Для практического исследования защищенного режима придется выполнить некоторую работу по переконфигурированию компьютера. В наше время компьютеры обычно конфигурируются так, что при их включении сразу загружается система Windows. Работы, для которых требуется DOS, выполняются либо в режиме эмуляции DOS, либо в сеансе DOS, организуемом системой Windows. Для запуска прикладной программы защищенного режима такой способ не годится. Нам понадобится DOS в "чистом виде", без следов Windows. Более того, перед запуском программы необходимо выгрузить все драйверы обслуживания расширенной памяти (HIMEM.SYS и EMM386.EXE) и программы, использующие расширенную память, например, SMARTDRV.EXE. Лучше всего загружать DOS с системной дискеты, подготовив файлы CONFIG.SYS и AUTOEXEC.BAT в минимальном варианте.
Обсуждая в начале этого раздела основы защищенного режима, мы не затронули многие, в том числе принципиальные вопросы, с которыми придется столкнуться при написании работоспособной программы. Необходимые пояснения будут даны в конце этого раздела.
Пример 4-4. Программирование защищенного режима
.586Р ;Разрешение трансляции всех команд МП 586
;Структура для описания дескрипторов сегментов
dcr struc ;Имя структуры
limit dw 0 ;Граница (биты 0...15)
base_l dw 0 ;База, биты 0...15
base_m db 0 ;База, биты 16...23
attr_l db 0 ;Байт атрибутов 1
attr_2 db ;Граница (биты 16...19) и атрибуты 2
base_h db 0 ;База, биты 24...31
dcr ends ;
data segment use16 ;
;Таблица глобальных дескрипторов GDT
gdt_null dcr <0,0,0,0,0,0> ;Селектор 0-обязательный
;нулевой дескриптор
gdt_data dcr <data_size-l,0,0,92h,0,0> ;Селектор 8,
;сегмент данных
gdt_code dcr <code_size-l,0,0,98h,0,0>;Селектор 16,
;сегмент команд
gdt_stack dcr <511,0,0,92h,0,0> ;Селектор 24 -
;сегмент стека
gdt_screen dcr <4095,B000h,OBh,92h,0,0> ;Селектор 32,
;видеобуфер
pdescr df 0 ;Псевдодескриптор для команды Igdt
data_size=$-gdt_null ;Размер сегмента данных
data ends ;Конец сегмента данных
text segment use16 ;Сегмент команд, 16-разрядный режим
assume CS:text,DS:data;
main proc ;
xor EAX,EAX ;Очистим ЕАХ
mov AX,data ;Загрузим в DS сегментный
mov DS,AX ;адрес сегмента данных
;Вычислим 32-битовый линейный адрес сегмента данных
;и загрузим его в дескриптор сегмента данных в GDT.
;В регистре АХ уже находится сегментный адрес.
;Умножим его на 16 сдвигом влево на 4 бита
shl ЕАХ,4 ;В ЕАХ линейный базовый адрес
mov EBP, ЕАХ ;Сохраним его в ЕВР для будущего
mov BX,offset gdt_data ;В ВХ адрес дескриптора
mov [BX].base_l,AX ;Загрузим младшую часть базы
rol ЕАХ,16 ;Обмен старшей и младшей половин ЕАХ
mov [BX].base_m,AL ;Загрузим среднюю часть базы
;Вычислим 32-битовый линейный адрес -сегмента команд
;и загрузим его в дескриптор сегмента команд в GDT
хог ЕАХ, ЕАХ ;Очистим ЕАХ
mov AX,CS ;Сегментный адрес сегмента команд
shl ЕАХ,4 ;В ЕАХ линейный базовый адрес
mov BX,offset gdt_code ;В ВХ адрес дескриптора
mov [BX] .base_l,AX ;Загрузим младшую часть базы
rol ЕАХ,16 ;Обмен старшей и младшей половин ЕАХ
mov [BX].base_m,AL ;Загрузим среднюю часть базы
;Вычислим 32-битовый линейный адрес сегмента стека
хог ЕАХ, ЕАХ ;Все, как и для других
mov AX,SS ;дескрипторов
shl ЕАХ,4
mov BX,offset gdt_stack
mov [BX].base_l,AX
rol EAX,16
mov [BX].base_m,AL
;Подготовим псевдодескриптор pdescr для загрузки регистра GDTR
mov dword ptr pdescr+2,EBP ;База GDT
mov word ptr pdescr, 39 ;Граница GDT
Igdt pdescr ;Загрузим регистр GDTR
cli ;Запрет прерываний
;Переходим в защищенный режим
mov EAX,CR0 ;Получим содержимое CR0
or EAX,1 ;Установим бит защищенного режима
mov CRO,ЕАХ ;Запишем назад в CR0
;---------------------------------------------------------;
;Теперь процессор работает в защищенном режиме ;
;---------------------------------------------------------;
;Загружаем в CS:IP селектор:смещение точки continue
db OEAh ;Код команды far jmp
dw offset continue ;Смещение
dw 16 ;Селектор сегмента команд
continue:
;Делаем адресуемыми данные
mov AX, 8 ;Селектор сегмента данных
mov DS,AX ;Загрузим в DS
;Делаем адресуемым стек
mov AX,24 ;Селектор сегмента стека
mov SS,AX ;Загрузим в SS
;Инициализируем ES и выводим символ
mov AX,32 ;Селектор сегмента видеобуфера
mov ES,AX ;Загрузим в ES
mov BX,2000 ;Начальное смещение на экране
mov AX,09FOFh ;Символ с атрибутом
mov ES : [BX] , АХ;Вывод в видеобуфер
;Вернемся в реальный режим
mov gdt_data.limit,0FFFFh ;Установим
mov gdt_code.limit,0FFFFh ;значение границы
mov gdt_stack.limit,0FFFFh;для реального
mov gdt_screen.limit,0FFFFh ;режима
mov AX,8 ;Загрузим теневой регистр
mov DS,AX ;сегмента данных
mov AX,24 ;To же для
mov SS,AX ;стека
mov AX,32 ;To же
mov ES, AX ;для регистра ES
;Выполним дальний переход, чтобы заново загрузить
;селектор в CS и модифицировать его теневой регистр
db0Eah ;Код команды jmp far
dwoffset go ;Смещение точки перехода
dw!6 ;Селектор сегмента команд
;Переключим режим процессора
go: mov EAX,CR0 ;Получим содержимое CR0
and EAX,0FFFFFFFEh;Сбросим бит РЕ
mov CR0,EAX ;Запишем назад в CR0
db0Eah ; Код команды far jmp
dwoffset return ;Смещение точки перехода
dwtext ;Сегментный адрес
;---------------------------------------------;
;Теперь процессор снова работает в реальном режиме ;
;---------------------------------------------;
;Восстановим операционную среду реального режима
return: mov AX,data ;Загрузим сегментный
mov DS,AX ;регистр DS
mov AX,stk ;Загрузим сегментный
mov SS,AX ;регистр SS
mov SP,512 ;Восстановим SP
sti ;Разрешим прерывания
mov AX,4C00h ;Завершим программу
;обычным образом
int 2 In main endp
code_size=$-main ;Размер сегмента команд
text ends /Конец сегмента команд
stk segment stack ;Сегмент
db 512 dup (') ;стека stk ends
end main ;Конец программы и точка входа
Для того, чтобы разрешить использование всех, в том числе привилегированных команд 32-разрядных процессоров, в программу включена директива .586Р.
Программа начинается с объявления структуры dcr, с помощью которой будут описываться дескрипторы сегментов. Сравнивая описание структуры dcr в программе с рис. 4.9, нетрудно проследить их соответствие друг другу. Для удобства программного обращения в структуре dcr база описывается тремя полями: младшим словом (base_l) и двумя байтами: средним (base_m) и старшим (base_h).
В байте атрибутов 1 задается ряд характеристик сегмента. В примере 4.4 используются сегменты двух типов: сегмент команд, для которого байт attr_l должен иметь значение 98h (присутствующий, только исполнение, DPL=0), и сегмент данных (или стека) с кодом 92h (присутствующий, чтение и запись, DPL=0).
Некоторые дополнительные характеристики сегмента указываются в старшем полубайте байта attr_2. Для всех наших сегментов значение этого полубайта равно 0 (бит G=0, так как граница указывается в байтах, а D=0, так как программа 16-разрядная).
Сегмент данных data начинается с описания важнейшей системной структуры - таблицы глобальных дескрипторов. Как уже отмечалось выше, обращение к сегментам в защищенном режиме возможно исключительно через дескрипторы этих сегментов. Таким образом, в таблице дескрипторов должно быть описано столько дескрипторов, сколько сегментов использует программа. В нашем случае в таблицу включены, помимо обязательного нулевого дескриптора, всегда занимающего первое место в таблице, четыре дескриптора для сегментов данных, команд, стека и дополнительного сегмента данных, который мы наложим на видеобуфер, чтобы обеспечить возможность вывода в него символов. Порядок дескрипторов в таблице (кроме нулевого) не имеет значения.
Поля дескрипторов для наглядности заполнены конкретными данными явным образом, хотя объявление структуры dcr с нулями во всех полях позволяет описать дескрипторы несколько короче, например:
gdt_null dcr <> ;Селектор 0 - обязательный
;нулевой дескриптор
gdt_data dcr <data_size - l, , , 92h> ;Селектор 8 - сегмент данных
В дескрипторе gdt_data, описывающем сегмент данных программы, заполняется поле границы сегмента (фактическое значение размера сегмента data_size будет вычислено транслятором, см. последнее предложение сегмента данных), а также байт атрибутов 1. База сегмента, т.е. линейный адрес его начата, в явной форме в программе отсутствует, поэтому ее придется программно вычислить и занести в дескриптор уже на этапе выполнения.
Дескриптор gdt_codc сегмента команд заполняется схожим образом.
Дескриптор gdt_stack сегмента стека имеет, как и любой сегмент данных, код атрибута 92h, что разрешает его чтение и запись, и явным образом заданную границу - 255 байт, что соответствует размеру стека. Базовый адрес сегмента стека так же придется вычислить на этапе выполнения программы.
Последний дескриптор gdt_scrcen описывает страницу 0 видеобуфера. Размер видеостраницы, как известно, составляет 4096 байт, поэтому в поле границы указано число 4095. Базовый физический адрес страницы известен, он равен BS000h. Младшие 16 бит базы (число 8000И) заполняют слово base_l дескриптора, биты 16...19 (число OBU) - байт base_m. Биты 20...31 базового адреса равны 0, поскольку видеобуфер размещается в первом мегабайте адресного пространства.
Первая половина программы посвящена подготовке перехода в защищенный режим. Прежде всего надо завершить формирование дескрипторов сегментов программы, в которых остались незаполненными базовые адреса сегментов.
Базовые (32-битовые) адреса определяются путем умножения значений сегментных адресов на 16. После обнуления регистра ЕАХ и инициализации сегментного регистра DS, которая позволит нам обращаться к полям данных программы в реальном режиме, содержимое ЕАХ командой sill сдвигается влево на 4 бита, образуя линейный 32-битовый адрес. Поскольку этот адрес будет использоваться и в последующих фрагментах программы, он запоминается в регистре ЕВР (или любом другом свободном регистре общего назначения). В ВХ загружается адрес дескриптора данных, после чего в дескриптор заносится младшая половина линейного адреса из регистра АХ. Поскольку к старшей половине регистра ЕАХ (где нас интересуют биты 17...24) обратиться невозможно, над всем содержимым ЕАХ с помощью команды rol выполняется циклический сдвиг на 16 бит, в результате которого младшая и старшая половины ЕАХ меняются местами.
После сдвига содержимое AL (где теперь находятся биты 17...24 линейного адреса) заносится в поле base_m дескриптора. Аналогично Вычисляются линейные адреса сегмента команд и сегмента стека.
Следующий этап подготовки к переходу в защищенный режим - загрузка в регистр процессора GDTR (Global Descriptor Table Register, регистр таблицы глобальных дескрипторов) информации о таблице глобальных дескрипторов. Эта информация включает в себя линейный базовый адрес таблицы и ее границу и размещается в 6 байтах поля данных, называемого иногда псевдодескриптором. Для загрузки GDTR предусмотрена специальная привилегированная команда Igdt (load global descriptor table, загрузка таблицы глобальных дескрипторов), которая требует указания в качестве операнда имени псевдодескриптора. Формат псевдодескриптора приведен на рис. 4.10.
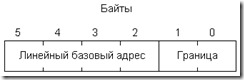
Рис. 4.10. Формат псевдодескриптора.
В нашем примере заполнение псевдодескриптора упрощается вследствие того, что таблица глобальных дескрипторов расположена в начале сегмента данных, и ее базовый адрес совпадает с базовым адресом всего сегмента, который мы благоразумно сохранили в регистре ЕВР. Границу GDT в нашем случае легко вычислить в уме: 5 дескрипторов по 8 байт занимают объем 40 байт, и , следовательно, граница равна 39. Команда Igdt загружает регистр GDTR и сообщает процессору о местонахождении и размере GDT.
Еще одна важная операция, которую необходимо выполнить перед переходом в защищенный режим, заключается в запрете всех аппаратных прерываний. Дело в том, что в защищенном режиме процессор выполняет процедуру прерывания не так, как в реальном. При поступлении сигнала прерывания процессор не обращается к таблице векторов прерываний в первом килобайте памяти, как в реальном режиме, а извлекает адрес программы обработки прерывания из таблицы дескрипторов прерываний, построенной схоже с таблицей глобальных дескрипторов и располагаемой в программе пользователя (или в операционной системе). В примере 4.4 такой таблицы
нет, и па время работы нашей программы прерывания придется запретить. Запрет всех аппаратных прерываний осуществляется командой cli.
Теперь, наконец, можно перейти в защищенный режим, что делается на удивление просто. Для перевода процессора в защищенный режим достаточно установить бит 0 в управляющем регистре CRO. Всего в процессоре имеется 4 программно-адресуемых управляющих регистра с мнемоническими именами CRO, CR1, CR2 и CR3. Регистр CR1 зарезервирован, регистры CR2 и CR3 управляют страничным преобразованием, которое у нас выключено, а регистр CRO содержит целый ряд управляющих битов, из которых нас сейчас будут интересовать только биты 31 (разрешение страничного преобразования) и 0 (включение защиты). При включении процессора оба эти бита сбрасываются, и в процессоре устанавливается реальный режим с выключенным страничным преобразованием. Установка в 1 младшего бита CR0 переводит процессор в защищенный режим, сброс этого бита возвращает его в режим реальных адресов.
Для того, чтобы в процессе установки бита 0 не изменить состояние других битов регистра CR0, сначала его содержимое считывается командой mov в регистр ЕАХ, там с помощью команды or устанавливается младший бит, после чего второй командой mov измененное значение загружается в CR0. Процессор начинает работать по правилам защищенного режима.
Хотя защищенный режим установлен, однако действия по настройке системы еще не закончены. Действительно, во всех используемых в программе сегментных регистрах хранятся не селекторы дескрипторов сегментов, а базовые сегментные адреса, не имеющие смысла в защищенном режиме. Между прочим, отсюда можно сделать вывод, что после перехода в защищенный режим программа не должна работать, так как в регистре CS пока еще нет селектора сегмента команд, и процессор не может обращаться к этому сегменту. В действительности это не совсем так.
В процессоре для каждого из сегментных регистров имеется так называемый теневой регистр дескриптора, который имеет формат дескриптора (рис. 4.11). Теневые регистры недоступны программисту; они автоматически загружаются процессором из таблицы дескрипторов каждый раз, когда процессор загружает соответствующий сегментный регистр. Таким образом, в защищенном режиме программист имеет дело с селекторами, т.е. номерами дескрипторов, а процессор - с самими дескрипторами, хранящимися в теневых регистрах. Именно содержимое теневого регистра (в первую очередь, линейный адрес сегмента) определяет область памяти, к которой обращается процессор при выполнении конкретной команды.
В реальном режиме теневые регистры заполняются не из таблицы дескрипторов, а непосредственно самим процессором. В частности, процессор заполняет поле базы каждого теневого регистра линейным базовым адресом сегмента, полученным путем умножения па 16 содержимого сегментного регистра, как это и положено в реальном режиме. Поэтому после перехода в защищенный режим в теневых регистрах находятся правильные линейные базовые адреса, и программа будет выполняться правильно, хотя с точки зрения правил адресации защищенного режима содержимое сегментных регистров лишено смысла.

Рис. 4.11. Сегментные регистры и теневые регистры дескрипторов.
Тем не менее после перехода в защищенный режим прежде всего следует загрузить в используемые сегментные регистры селекторы соответствующих сегментов. Это позволит процессору правильно заполнить все поля теневых регистров из таблицы дескрипторов. Пока эта операция не выполнена, некоторые поля теневых регистров (в частности, границы сегментов) содержат неверную информацию.
Загрузить селекторы в сегментные регистры DS, SS и ES не представляет труда. Но как загрузить селектор в регистр CS, в который запрещена прямая запись? Для этого можно воспользоваться искусственно сконструированной командой дальнего перехода, которая, как известно, приводит к смене содержимого и IP, и CS. Фрагмент
db OEAh ;Код команды far jmp
dw offset continue ;Смещение
dw 16 ;Селектор сегмента команд
выглядящий совершенно нелепо в сегменте команд, как раз и демонстрирует эту методику. В реальном режиме мы поместили бы во второе слово адреса сегментный адрес сегмента команд, в защищенном же мы записываем в него селектор этого сегмента (число 16).
Команда дальнего перехода, помимо загрузки в CS селектора, выполняет еще одну функцию - она очищает очередь команд в блоке предвыборки команд процессора. Как известно, в современных процессорах с целью повышения скорости выполнения программы используется конвейерная обработка команд программы, позволяющая совместить во времени фазы их обработки. Одновременно с выполнением текущей (первой) команды осуществляется выборка операндов следующей (второй), дешифрация третьей и выборка из памяти четвертой команды. Таким образом, в момент перехода в защищенный режим уже могут быть расшифрованы несколько следующих команд и выбраны из памяти их операнды. Однако эти действия выполнялись, очевидно, по правилам реального, а не защищенного режима, что может привести к нарушениям в работе программы. Команда перехода очищает очередь предвыборки, заставляя процессор заполнить ее заново уже в защищенном режиме.
Далее выполняется загрузка в сегментные регистры DS и SS значений соответствующих селекторов, и на этом, наконец, заканчивается процедура перехода в защищенный режим.
Следующий фрагмент программы является, можно сказать, диагностическим. В нем инициализируется (по правилам защищенного режима!) сегментный регистр ES и в видеобуфер из регистра АХ выводится один символ. Код 0Fh соответствует изображению большой звездочки, а атрибут 9Fh - ярко-белому мерцающему символу на синем поле. Появление этого символа на экране служит подтверждением правильного функционирования программы в защищенном режиме.
Почему мы не предусмотрели вывод на экран хотя бы одной содержательной строки? Дело в том, что в защищенном режиме запрещены любые обращения к функциям DOS или BIOS. Причина этого совершенно очевидна - и DOS, и BIOS являются программами реального режима, в которых широко используется сегментная адресация реального режима, т.е. загрузка в сегментные регистры сегментных адресов. В защищенном же режиме в сегментные регистры загружаются не сегментные адреса, а селекторы. Кроме того, обращение к функциям DOS и BIOS осуществляется с помощью команд программного прерывания int с определенными номерами, а в защищенном режиме эти команды приведут к совершенно иным результатам. Поэтому в программе, работающей в защищенном режиме и не имеющей специальных и довольно сложных средств перехода в так называемый режим виртуального 86-го процессора, вывод на экран можно осуществить только прямым программированием видеобуфера. Нельзя также выполнить запись или чтение файла; более того, нельзя даже завершить программу средствами DOS. Сначала се надо вернуть в реальный режим.
Возврат в реальный режим можно осуществить разными способами. Мы воспользуемся для этого тем же регистром CRO, с помощью которого мы перевели процессор а защищенный режим. Казалось бы, для возврата в реальный режим достаточно сбросить бит 0 этого регистра. Однако дело обстоит не так просто. Для корректного возврата в реальный режим надо выполнить некоторые подготовительные операции, рассмотрение которых позволит нам глубже вникнуть в различия реального и защищенного режимов.
При работе в защищенном режиме в дескрипторах сегментов записаны, среди прочего, их линейные адреса и границы. Процессор при выполнении команды с адресацией к тому или иному сегменту сравнивает полученный им относительный адрес с границей сегмента и, если команда пытается адресоваться за пределами сегмента, формирует прерывание (исключение) нарушения общей защиты. Если в программе предусмотрена обработка исключений, такую ситуацию можно обнаружить и как то исправить. Таким образом, в защищенном режиме программа не может выйти за пределы объявленных ею сегментов, а также не может выполнить действия, запрещенные атрибутами сегмента. Так, если сегмент объявлен исполняемым (код атрибута 1 981т), то данные из этого сегмента нельзя читать или модифицировать; если атрибут сегмента равен 92h, то в таком сегменте не может быть исполняемых команд, на зато данные можно как читать, так и модифицировать. Указав для какого-то сегмента код атрибута 90h, мы получим сегмент с запрещением записи. При попытке записи в этот сегмент процессор сформирует исключение общей защиты.
Как уже отмечалось, дескрипторы сегментов хранятся в процессе выполнения программы в теневых регистрах (см. рис. 4.11), которые загружаются автоматически при записи в сегментный регистр селектора.
При работе в реальном режиме некоторые поля теневых регистров должны быть заполнены вполне определенным образом. В частности, поле границы любого сегмента должно содержать число FFFFh, а бит дробности сброшен. Следует подчеркнуть, что границы всех сегментов должны быть точно равны FFFFh; любое другое число, например, FFFEh, "не устроит" реальный режим.
Если мы просто перейдем в реальный режим сбросом бита 0 в регистре CR0, то в теневых регистрах останутся дескрипторы защищенного режима и при первом же обращении к любому сегменту программы возникнет исключение общей защиты, так как ни один из наших сегментов не имеет границы, равной FFFFh. Поскольку мы не обрабатываем исключения, произойдет либо сброс процессора и перезагрузка компьютера, либо зависание. Таким образом, перед переходом в реальный режим необходимо исправить дескрипторы всех наших сегментов: команд, данных, стека и видеобуфера К сегментным регистрам FS и GS мы не обращались, и о них можно не заботиться.
Теневые регистры, куда, собственно, надо записать значение границы, нам недоступны. Для из модификации придется прибегнуть к окольному маневру: записать в поля границ всех четырех дескрипторов значение FFFFh, а затем повторно загрузить селекторы в сегментные регистры, что приведет к перезаписи содержимого теневых регистров. С сегментным регистром CS так поступить нельзя, поэтому его загрузку придется выполнить, как и ранее, с помощью искусственно сформированной команды дальнего перехода.
Настроив все использовавшиеся в программе сегментные регистры, можно сбросить бит 0 в CR0. После перехода в реальный режим нам придется еще раз выполнить команду дальнего перехода, чтобы очистить очередь команд в блоке предвыборки и загрузить в регистр CS вместо хранящегося там селектора обычный сегментный адрес регистра команд.
Теперь процессор снова работает в реальном режиме, причем, хотя в сегментных регистрах DS, ES и SS остались незаконные для реального режима селекторы, программа будет какое-то время выполняться правильно, так как в теневых регистрах находятся правильные линейные адреса (оставшиеся от защищенного режима) и законные для реального режима границы (загруженные туда нами). Если, однако, в программе встретятся команды сохранения и восстановления содержимого сегментных регистров, например
push DS
...
pop DS
выполнение программы будет нарушено, так как команда pop DS загрузит в DS не сегментный адрес реального режима, а селектор, т.е. число 8 в нашем случае. Это число будет рассматриваться процессором, как сегментный адрес, и дальнейшие обращения к полям данных приведут к адресации физической памяти начиная с абсолютного адреса 80h, что, конечно, лишено смысла. Даже если в нашей программе нет строк сохранения и восстановления сегментных регистров, они неминуемо встретятся, как только произойдет переход в DOS по команде int 21h, так как диспетчер DOS сохраняет, а затем восстанавливает все регистры задачи, в том числе и сегментные. Поэтому после перехода в реальный режим необходимо загрузить в используемые далее сегментные регистры соответствующие сегментные адреса, что и выполняется в программе для регистров DS и SS. Надо также не забыть разрешить запрещенные нами ранее аппаратные прерывания (команда sti).
Можно еще заметить, что в той части программы, которая выполняется в защищенном режиме, не используется стек. Учитывая это, можно было несколько сократить текст программы, удалив из нее строки настройки регистра SS как при подготовке перехода в защищенный режим, так и при возврате в реальный. Не было также необходимости заново инициализировать указатель стека, так как его исходное содержимое - смещение дна стека, равное 512, никуда из SP не делось бы.
Программа завершается обычным образом функцией DOS 4Ch. Нормальное завершение программы и переход в DOS в какой-то мере свидетельствует о ее правильности.
У рассмотренной программы имеется серьезный недостаток - полное отсутствие средств отладки. Для отладки программ защищенного режима используется механизм прерываний и исключений, в нашей же программе этот механизм не активизирован. Поэтому всякие неполадки при работе в защищенном режиме, которые с помощью указанного механизма можно было бы обнаружить и проанализировать, в данном случае будут приводить к сбросу процессора.
В приведенном примере проиллюстрированы лишь базовые средства программирования защищенного режима: понятие селекторов и дескрипторов, создание глобальной таблицы дескрипторов, переход в защищенный режим и обратно, адресация в защищенном режиме. За кадром остались такие важные вопросы, как обработка исключений и аппаратных прерываний, уровни привилегий и защита по привилегиям, раздельные операционные среды и таблицы локальных дескрипторов, создание и взаимодействие задач, режим виртуального процессора 8086 и другие.