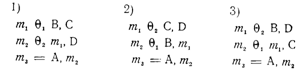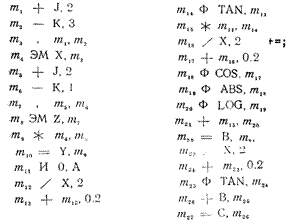Тестирование по принципу белого ящика характеризуется степенью, в какой тесты выполняют или покрывают логику (исходный текст) программы. Как показано в гл. 2, исчерпывающее тестирование по принципу белого ящика предполагает выполнение каждого пути в программе; но поскольку в программе с циклами выполнение каждого пути обычно нереализуемо, то тестирование всех путей не рассматривается в данной книге как перспективное.
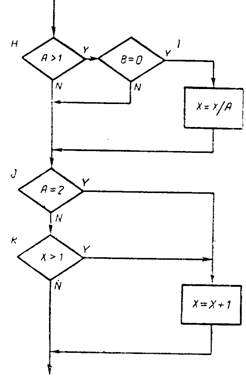
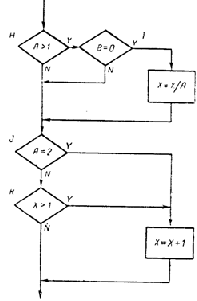
Если отказаться полностью от тестирования всех путей, то можно показать, что критерием покрытия является выполнение каждого оператора программы, по крайней мере, один раз. К сожалению, это слабый критерий, гак как выполнение каждого оператора, по крайней мере, один раз есть необходимое, но недостаточное условие для приемлемого тестирования по принципу белого ящика (рис. 4.1). Предположим, что на рис. 4.1 представлена небольшая программа, которая должна быть
протестирована. Эквивалентная программа, написанная на языке PL/I, имеет вид:
М: PROCEDURE (А, В, X);
IF ((А>1) & (В=0)) THEN DO; Х=Х/А; END;
IF ((A==2) I (X>D) THEN DO:X=X+1; END;
END;
Можно выполнить каждый оператор, записав один-единственный тест, который реализовал бы путь- асе. Иными словами, если бы в точке а были установлены значения A=2, В=0 и Х=3, каждый оператор выполнялся бы один раз (в действительности Х может принимать любое значение). К сожалению, этот критерий хуже, чем он кажется на первый взгляд. Например, пусть первое решение записано как или, а не как и. При тестировании по данному критерию эта ошибка не будет обнаружена. Пусть второе решение записано в программе как Х>0, эта ошибка также не будет обнаружена. Кроме того, существует путь, в котором Х не изменяется (путь abd). Если здесь ошибка, то и она не будет обнаружена. Таким образом, критерий покрытия операторов является настолько слабым, что его обычно не используют.
Более сильный критерий покрытия логики программы известен как покрытие решений, или покрытие переходов. Согласно данному критерию должно быть записано достаточное число тестов, такое, что каждое решение на этих тестах примет значение истина и ложь, по крайней мере, один раз. Иными словами, каждое направление перехода должно быть реализовано, по крайней мере, один раз. Примерами операторов перехода или решений являются операторы DO (или PERFORM UNTIL в Коболе), IF, многовыходные операторы GO ТО.
Можно показать, что покрытие решений обычно удовлетворяет критерию покрытия операторов. Поскольку каждый оператор лежит на некотором пути, исходящем либо из оператора перехода, либо из точки входа программы, при выполнении каждого направления перехода каждый оператор должен быть выполнен. Однако существует, по крайней мере три исключения. Первое— патологическая ситуация, когда программа не имеет решений. Второе встречается в программах или подпрограммах с несколькими точками входа; данный оператор может быть выполнен только в том случае, если выполнение программы начинается с соответствующей точки входа. Третье исключение—операторы внутри ON-единнц; выполнение каждого направления перехода не обязательно будет вызывать выполнение всех ON-единиц. Так как покрытие операторов считается необходимым условием, покрытие решений, которое представляется более сильным критерием, должно включать покрытие операторов. Следовательно, покрытие решений требует, чтобы каждое решение имело результатом значения истина и ложь, и при этом каждый оператор выполнялся бы, по крайней мере, один раз. Альтернативный и более легкий способ выражения этого требования состоит в том, чтобы каждое решение имело результатом значения истина и ложь и что каждой точке входа (включая ON-единицы) должно быть передано управление при вызове программы, по крайней мере, один раз.
Изложенное выше предполагает только двузначные решения или переходы и должно быть модифицировано для программ, содержащих многозначные решения. Примерами таких программ являются программы на PL/I, включающие операторы SELECT (CASE) или операторы GO ТО, использующие метку-переменную, программы на Фортране с арифметическими операторами IF, вычисляемыми операторами GO ТО или операторами GO ТО по предписанию, и программы на Коболе, содержащие операторы GO ТО вместе с ALTER или операторы GO— ТО—DEPENDING—ON. Критерием для них является выполнение каждого возможного результата всех решений по крайней мере один раз и передача управления при вызове программы или подпрограммы каждой точке входа по крайней мере один раз.
В программе, представленной на рис. 4.1, покрытие решений может быть выполнено двумя тестами, покрывающими либо пути асе и abd, либо пути acd и abe. Если мы выбираем последнее альтернативное покрытие, то входами двух тестов являются А=3, В=0, Х=3 и А=2, В=1,Х=1.
Покрытие решений — более сильный критерий, чем покрытие операторов, но н он имеет свои недостатки. Например, путь, где Х не изменяется (если выбрано первое альтернативное покрытие), будет проверен с вероятностью 50%. Если во втором решении существует ошибка (например, Х<1 вместо Х>1), то ошибка не будет обнаружена двумя тестами предыдущего примера.
Лучшим критерием по сравнению с предыдущим, является покрытие условий. В этом случае записывают число тестов, достаточное для того, чтобы все возможные результаты каждого условия в решении выполнялись по крайней мере один раз. Поскольку, как и при покрытии решений, это покрытие не всегда приводит к выполнению каждого оператора, к критерию требуется дополнение, которое заключается в том, что каждой точке входа в программу или подпрограмму, а также ON-единицам должно быть передано управление при вызове по крайней мере один раз. Например, оператор цикла
DO К=0 ТО 50 WHILE (J+K<QUEST);
содержит два условия: К меньше или равно 50 и J+K меньше, чем QUEST. Следовательно, здесь требуются тесты для ситуаций J£50, K>50 (т.е. выполнение последней итерации цикла), J+K<QUEST и J+К³ QUEST.
Программа рис. 4.1 имеет четыре условия: А> 1, В=0, А=2 и Х>1. Следовательно, требуется достаточное число тестов, такое, чтобы реализовать ситуации, где А>1, А£1, В¹0 и В=О в точке а и А=2,А¹2, X>1, и Х£1 в точке b. Тесты, удовлетворяющие критерию покрытия условий, и соответствующие им пути:
1. А=2, В=0, Х=4 асе
2. А=1, .B=1, X=1 abd.
Заметим, что, хотя аналогичное число тестов для этого примера уже было создано, покрытие условий обычно лучше покрытия решений, поскольку оно может (но не всегда) вызвать выполнение решений в условиях, не реализуемых при покрытии решений. Например, оператор
DO К=0 ТО 50 WHILE (J+K<QUEST);
представляет собой двузначный переход (либо выполняется тело цикла, либо выход из цикла). Если использовать тестирование решений, то достаточно выполнить цикл при изменении K от 0 до 51 без проверки случая, когда условие в WHILE ложно. Однако при критерии покрытия условий необходим тест, который реализовал бы результат ложь условия J+ K<QUEST.
Хотя применение критерия покрытия условий на первый взгляд удовлетворяет критерию покрытия решений, это не всегда так. Если тестируется решение IF (А&В), то при критерии покрытия условий требовались бы два теста — А есть истина, В есть ложь и А есть ложь, В есть истина. Но в этом случае не выполнялось бы THEN — предложение оператора IF. Тесты критерия покрытия условий для ранее рассмотренного примера покрывают результаты всех решений, но это только случайное совпадение. Например, два альтернативных теста

1. A=1, B=0, X=3
2. A=2, B=1, X=1
покрывают результаты всех условий, но только два из четырех результатов решений (они оба покрывают путь abe и, следовательно, не выполняют результат истина первого решения и результат ложь второго решения).
Очевидным следствием из этой дилеммы является критерий, названный покрытием решений/условий. Он требует такого достаточного набора тестов, чтобы все возможные результаты каждого условия в решении выполнялись по крайней мере один раз, все результаты каждого решения выполнялись по крайней мере один раз и каждой точке входа передавалось управление по крайней мере один раз.
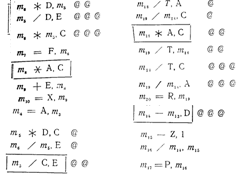
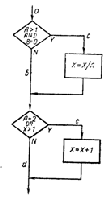
Недостатком критерия покрытия решений/условий является невозможность его применения для выполнения всех результатов всех условий; часто подобное выполнение имеет место вследствие того, что определенные условия скрыты другими условиями. В качестве примера рассмотрим приведенную на рис. 4.2 схему передач управления в машинном коде программы рис. 4.1. Многоусловные решения исходной программы здесь разбиты на отдельные решения и переходы, поскольку большинство машин не имеет команд, реализующих решения c многими исходами. Наиболее полное покрытие тестами в этом случае осуществляется таким образом, чтобы выполнялись все возможные результаты каждого простого решения. Два предыдущих теста критерия покрытия решений не выполняют этого; они недостаточны для выполнения результата ложь решения Н и результата истина решения К. Набор тестов для критерия покрытия условий такой программы также является неполным; два теста (которые случайно удовлетворяют также и критерию покрытия решений/условий) не вызывают выполнения результата ложь решения 1 и результата истина решения К.
Причина этого заключается в том, что, как показано на рис. 4.2, результаты условий в выражениях и и или могут скрывать и блокировать действие других условий. Например, если условие и есть ложь, то никакое из последующих условий в выражении не будет выполнено. Аналогично если условие или есть истина, то никакое из последующих условий не будет выполнено. Следовательно, критерии покрытия условий и покрытия решений/условий недостаточно чувствительны к ошибкам в логических выражениях.
Критерием, который решает эти и некоторые другие проблемы, является комбинаторное покрытие условий. Он требует создания такого числа тестов, чтобы все возможные комбинации результатов условия в каждом решении и все точки входа выполнялись по крайней мере один раз. Например, в приведенной ниже последовательности операторов
NOTFOUND=’1’В;
DO I=1 ТО TABSIZE WHILE (NOTFOUND); /* поиск в таблице */
последовательность операторов, реализующая процедуру поиска,
END;
существуют четыре ситуации, которые должны быть протестированы: .
1. I £ TABSIZE и NOTFOUND есть истина.
2. I £ TABSIZE и NOTFOUND есть ложь (обнаружение необходимого искомого значения до достижения конца таблицы).
3. I > TABSIZE и NOTFOUND есть истина (достижение конца таблицы без обнаружения искомого значения).
4. I >TABSIZE и NOTFOUND есть ложь (искомое значение является последней записью в таблице).
Легко видеть, что набор тестов, удовлетворяющий критерию комбинаторного покрытия условий, удовлетворяет также и критериям покрытия решений, покрытия условий и покрытия решений/условий.
По этому критерию в программе рис. 4.1 должны быть покрыты тестами следующие восемь комбинаций:
1.A > 1, В = 0 5.А = 2, Х > 1
2.A > 1. B ¹ 0 6.A = 2, X £ l
3.A £ 1 ,В = 0 7.A ¹ 2, X > 1
4.A £ 1, В ¹ 0 8.A ¹ 2, X £ I
Заметим, что комбинации 5—8 представляют собой значения второго оператора IF. Поскольку Х может быть изменено до выполнения этого оператора, значения, необходимые для его проверки, следует восстановить исходя из логики программы с тем, чтобы найти соответствующие входные значения.
Для того чтобы протестировать эти комбинации, необязательно использовать все восемь тестов. Фактически они могут быть покрыты четырьмя тестами. Приведем входные значения тестов и комбинации, которые они покрывают:
A=2, В=0, Х=4 покрывает 1,5
А=2, В=1,Х=1 покрывает 2,6
А=1, В=0, Х=2 покрывает 3,7
А=1, В=1, Х=1 покрывает 4,8
То, что четырем тестам соответствуют четыре различных пути на рис. 4.1, является случайным совпадением. На самом деле представленные выше тесты не покрывают всех путей, они пропускают путь acd. Например, требуется восемь тестов для тестирования следующей программы:
IF((X=Y) & (LENGTH(Z)=0) &END)THEN J-l; ELSE I=l;
хотя она покрывается лишь двумя путями. В случае циклов число тестов для удовлетворения критерию комбинаторного покрытия условий обычно больше, чем число путей.
Таким образом, для программ, содержащих только одно условие на каждое решение, минимальным является критерий, набор тестов которого 1) вызывает выполнение всех результатов каждого решения по крайней мере один раз и 2) передает управление каждой точке входа (например, точке входа, ON-единице) по крайней мере один раз (чтобы обеспечить выполнение каждого оператора программы по крайней мере один раз). Для программ, содержащих решения, каждое из которых имеет более одного условия, минимальный критерий состоит из набора тестов, вызывающих выполнение всех возможных комбинаций результатов условий в каждом решении и передающих управление каждой точке входа программы по крайней мере один раз. (Слово «возможных» употреблено здесь потому, что некоторые комбинации условий могут быть нереализуемыми; например, в выражении (А>2)&(A<10) могут быть реализованы только три комбинации условий.)